Classifier
Ⅰ. Basic Introduction
1. What is Classifier
Classifier is a general term for classifying samples in data mining.
To give you an intuitive idea of classification, let's look at two examples:
Wine recognition: we measured the color (wavelength) and alcohol concentration of a bottle of wine. Based on these data, machine should determine whether the bottle is beer, red wine or spirits.
Disease judgment: the patient goes to the hospital to do a lot of tests like liver function tests, blood tests. Input these data into a machine, and the machine would determine whether the patient is sick and what disease he/she has got based on these data.

This machine, which can automatically classify input, is called a classifier.
For human, we may be able to make a simple identification of alcohol with our eyes, but it's not that easy to judge diseases. At this point, if there is a classifier for disease judgment, we just have to input the corresponding test data, and a judgment can be obtained.
What the classifier can do based on artificial intelligence is more than disease judgment. It can achieve more complex judgment with more features. For computers, storage and computing are what they excel in. With such a powerful classifier, artificial intelligence can help us to do almost all complex judgments in the future. Make better use of artificial intelligence, you can get the first chance in the future.
There are many ways to implement classifier, one of which is the deep learning based on neural network.
2. The Principle of AI Classifier (Neural Network)
The neural network model originates from an algorithm that attempts to make machines imitate the brain, connecting the neurons that mimic the neurons to form a network image.
As picture below:
The complete neural network consists of input layer (4 input units), hidden layer (2 layers, 4 and 3 hidden units) and output layer (2 output units).
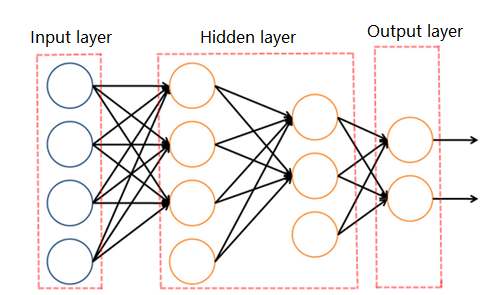
Input layer:input the features that need to be predicted。
For example:
In wine recognition, the features of wine is its color and alcohol concentration;
In disease judgment, the features of disease is multiple data.
Hidden layer: through the complex hidden layer structure, the salient features in the input data are extracted, and the results are transmitted to the output layer.
The hidden layer can be either single-layer or multi-layer, with a certain number of neurons in each layer.
Output layer: the layer with different output classification results is called the output layer.
For example:
In wine recognition, the output results are beer, red wine and spirits;
In disease judgment, the output results are healthy, cold, fever, etc.
In brief, the whole neural network collects the information through the input layer, uses the hidden layer to carry on the operation and process the information, and outputs the classification results to the output layer. Thus the function of the classifier is realized.
3. Training and Prediction of Neural Network
Classifiers need to be trained to roughly predict the classification results.
For example:
Who is better able to distinguish wine, a person who has never seen wine or a person who has a good knowledge of wine?- The answer is obviously the latter. A person who has drunk a lot of wine and has a lot of research on it, knows the type and taste of the wine. The more times he drinks, the more varieties of wine he knows.
Similarly, for classifiers, it also requires to be continuously trained with a large number of training data. Each group of training data needs to contain all the features and classification categories.
It's like training a man who doesn't know how to drink. Having trained for enough times, he could tell the type of wine.
Whether the prediction result is accurate or not is related to the structure of neural network, the number of times of training, and even some random factors in training.
Ⅱ. Classifier Blocks
1.Matrix data

Data can be used to directly access a specified row or column of a matrix
There are two types of matrix data:
Related data in excel form uploaded by the user The system will store the data as matrix data, that is, two-dimensional array.
In order to may the user to learn and to use blocks easier, the system prefabricates four groups of training data: UpDown-Distribution-Matrix, LeftRight-Distribution-Matrix, Round-Distribution-Matrix and Spiral-Distribution-Matrix, which were stored as matrix data

2. Set up training features and classification data

- Training features have to be numbers, otherwise it would be ignored by the system.

Classification data: data can be numbers or strings, the system would automatically identify the total number of categories. (The output layer currently supports only two categories, otherwise it cannot be run.))
For example:
As figure 1, it is a typical training data structure. In this matrix, each row is a set of data.
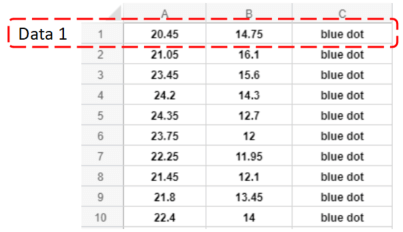
The data in red frame is one set of these data: Data 1.
The value in A1 (20.45) and B1 (14.75) are two features of Data 1.
The data in C1 is the output classification result of Data 1.

The whole matrix is formed by training features and classification of all sets.
List A and List B are the training features, and List C is the classification results under these features: blue dot and red dot.
Two standard usages of training data blocks:
- List form
Create new list in Data in sidebar:

The list data can be called directly by entering the corresponding data:


- Matrix form
Upload local excel file or use the 4 matrix data prefabricated by the system.
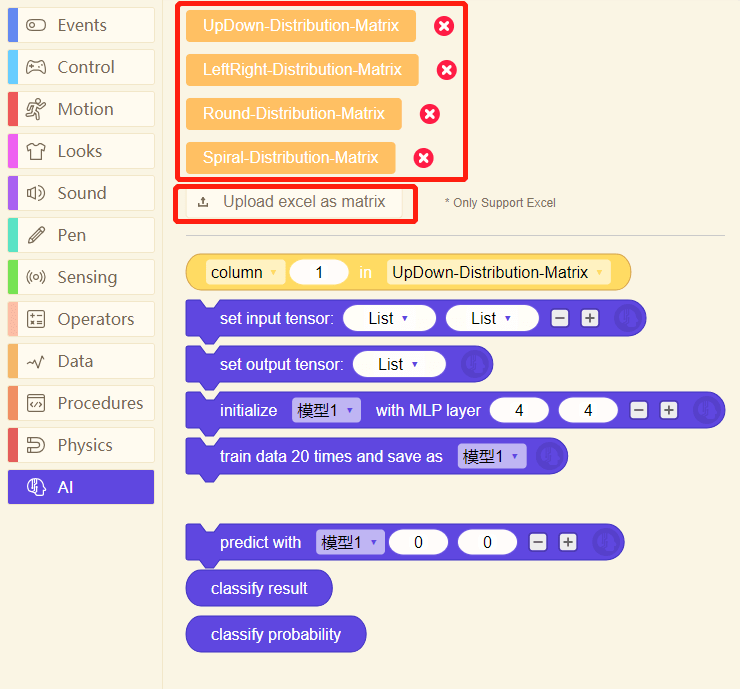
Data can be called by these blocks.


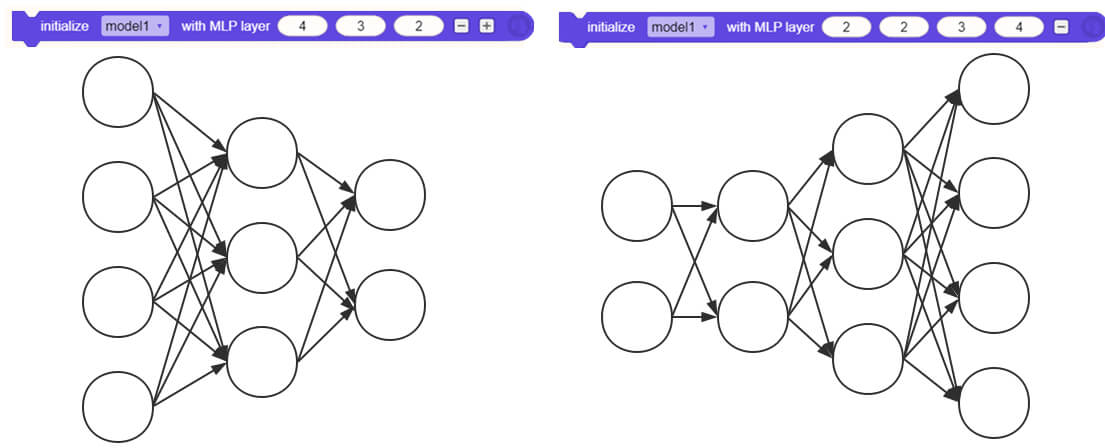
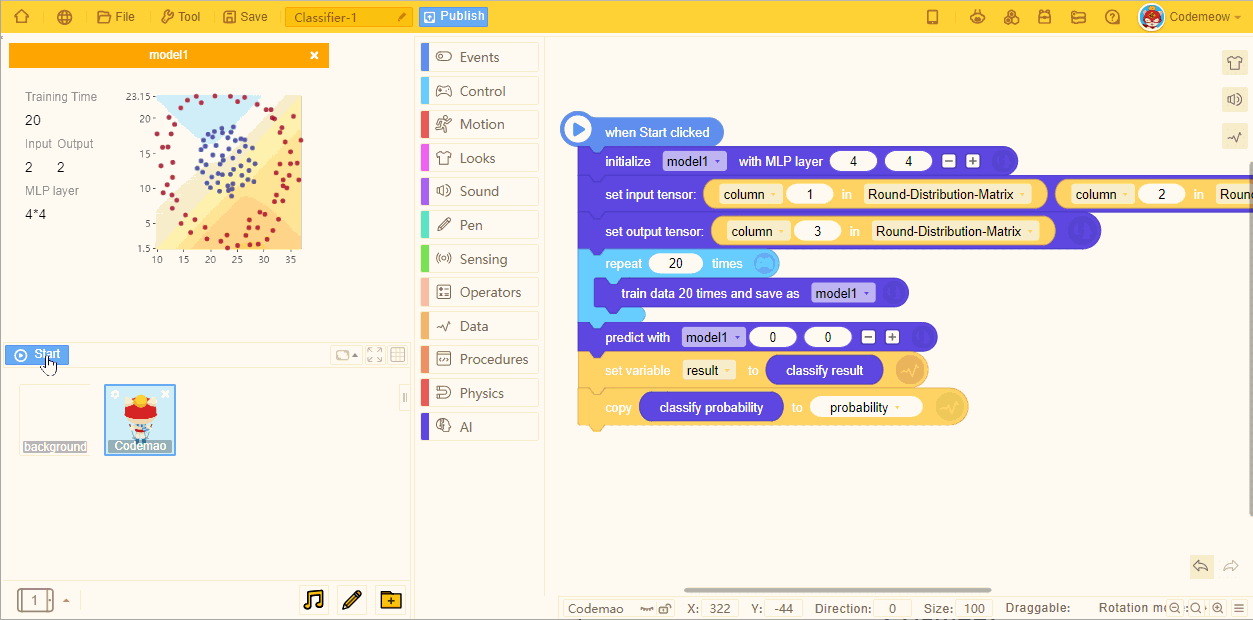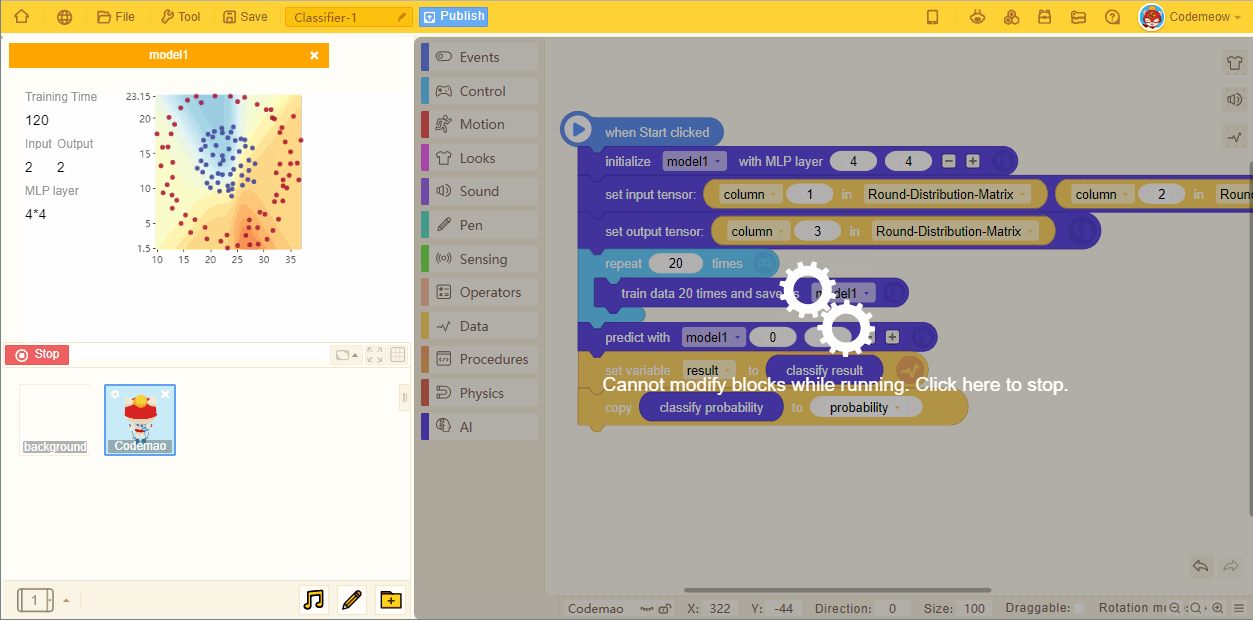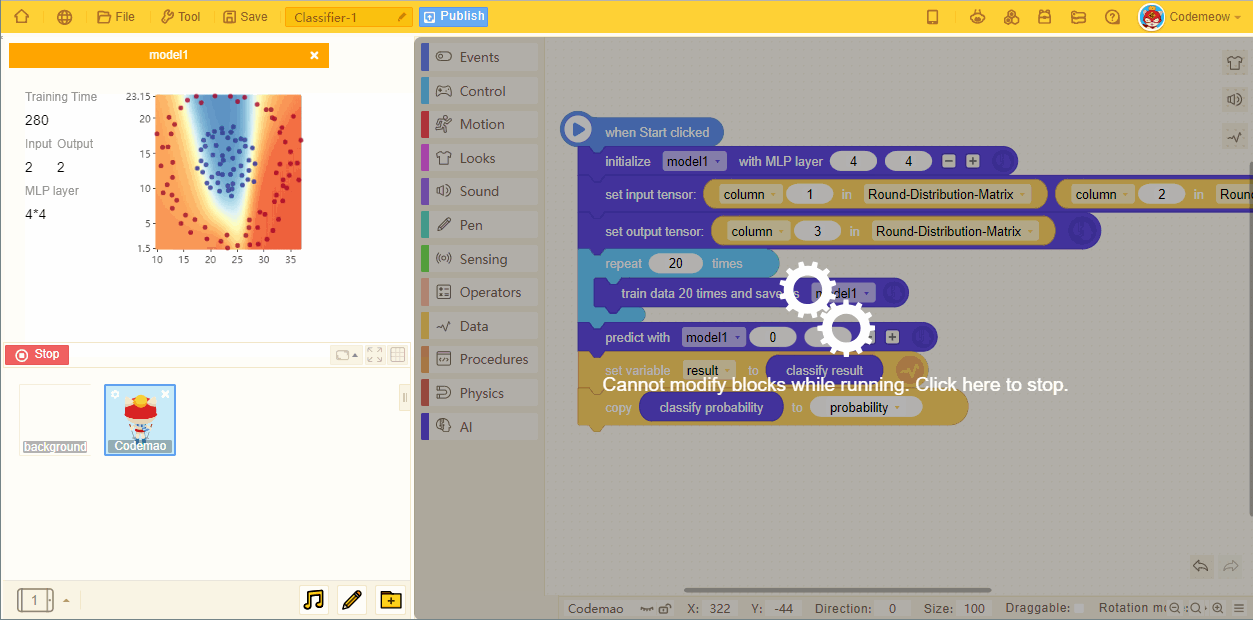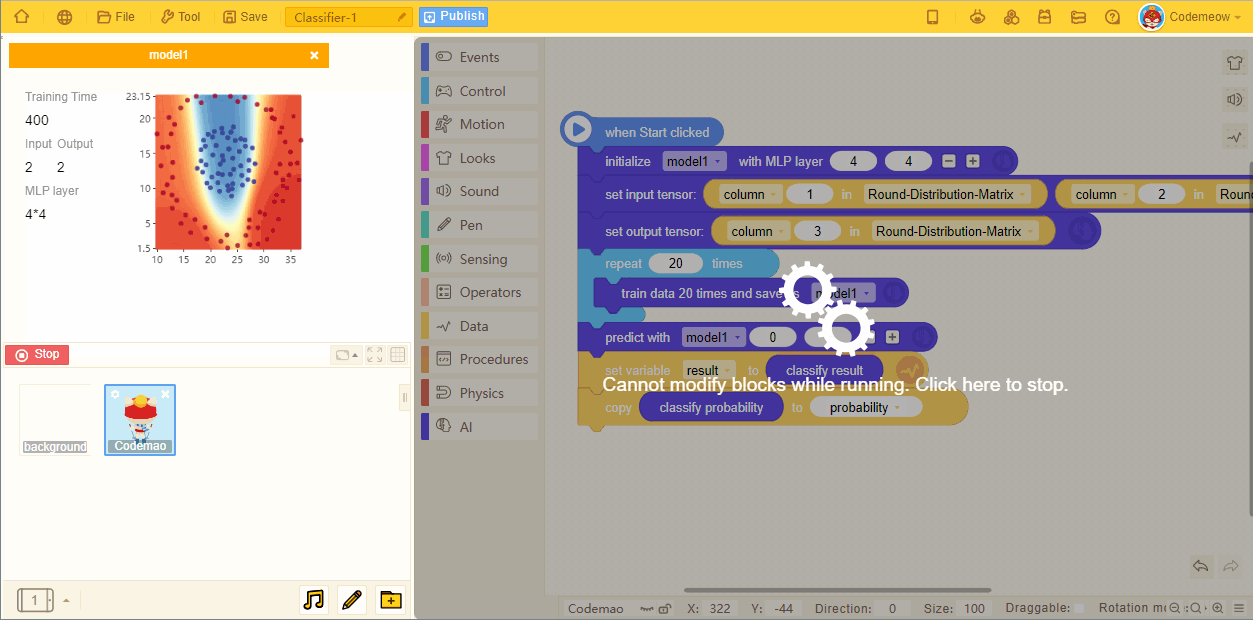
3、Neural network structure (MLP layer block)

Set the structure of hidden layer of neural network.
- The hidden layer can be a single layer or multiple layers. Different hidden layer structures of neural network have different effects on the final training results.
4. Back-propagation algorithm (training block)

Use a specific algorithm to train a set of training data, and save as a model.
- The training times of a single block is 20. Repeat blocks is required for training more than 20 times.
In training, the relevant training information will be shown on stage.
- When the input layer (training features) is 2, a training image with model prediction would appear.
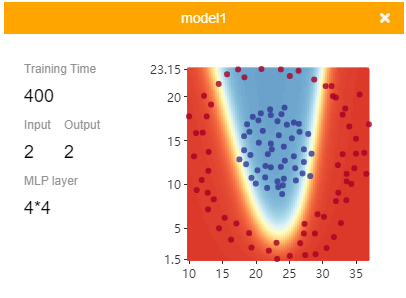
- When the input layer (training features) is not 2, the prediction image cannot be shown.

- As the number of training increases, the predicted models become more accurate:
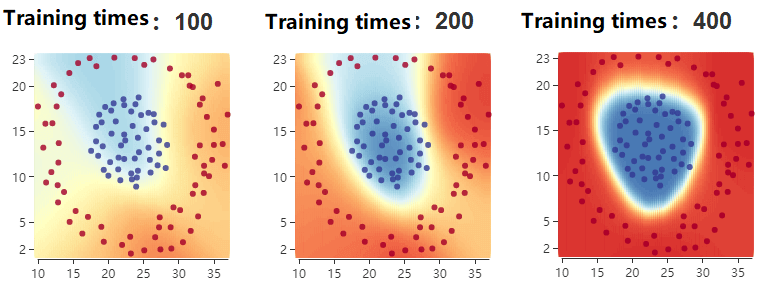
5. Prediction block

Save the trained data as a model and predict the new input features.
- Please note: the number of predicted features should be consistent with that of the original training data, otherwise the results cannot be predicted.
The predicted results are in two forms:
Classify result

Function: direct display of predicted classification results, and output them in the form of variables.

Pattern:

Classify probabolity

Function: show the probability of different classification results in sets of features, and output them in the form of a list.

Pattern:
